🛠 The Learnable Handwriter Complete Tutorial
For any questions regarding data preparation/training or application to palaeographical data contact:
matenia03[at]gmail[dot]com. For questions related to the architecture, contact: y.siglidis[at]gmail[dot]com This page provides a comprehensive guide for using the Learnable Handwriter. The Learnable Handwriter is an adaptation of The Learnable Typewriter: A Generative Approach to Text Analysis for palaeographical morphological analysis.The tutorial covers preparing data, training and fine-tuning models, as well as best practices.
Table of Contents
Data Format
Your dataset must follow a specific structure for the system to work correctly. You will need to create a datasets/name-of-your-dataset directory containing extracted images of text lines as well as their annotations in an annotation.json, as illustrated in the image below.
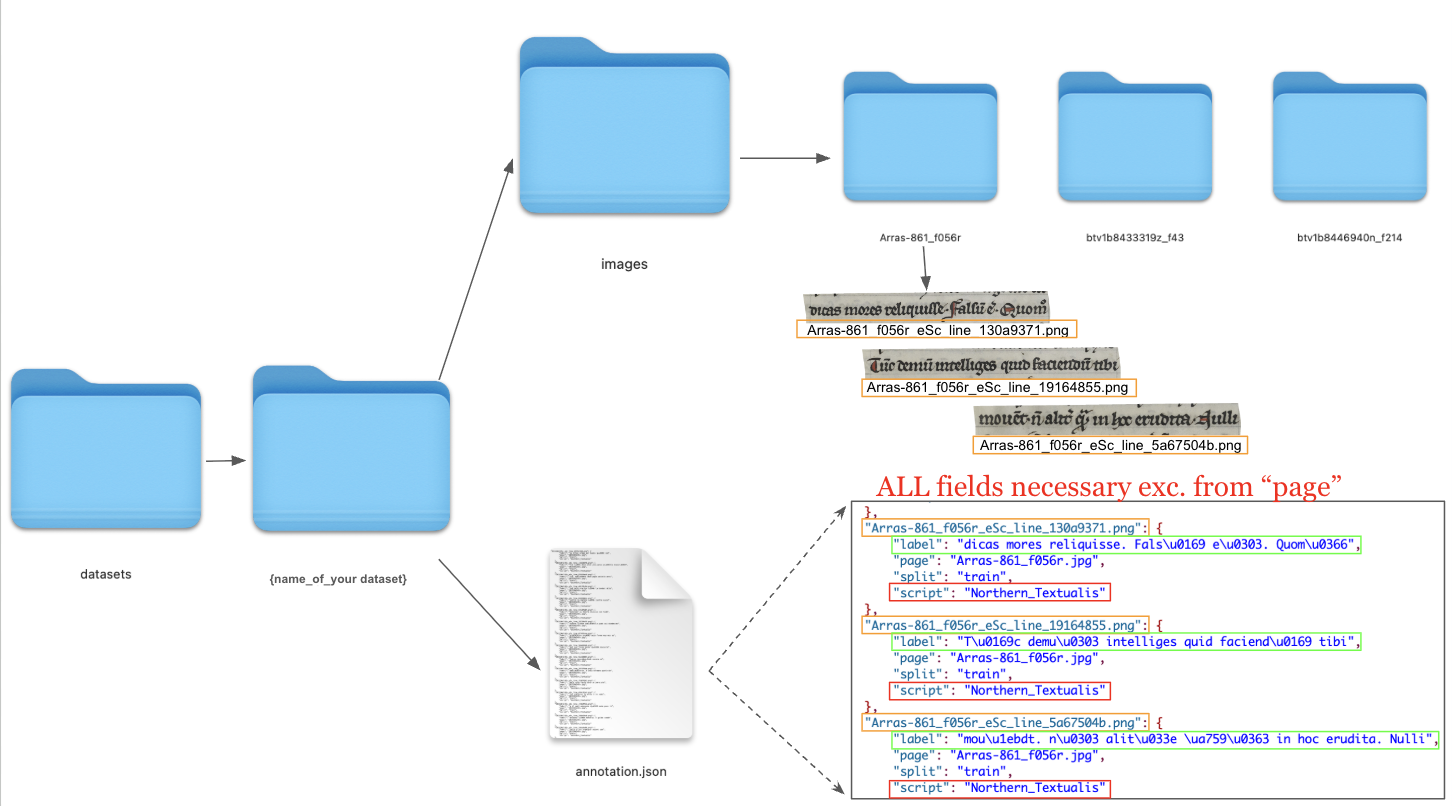
Image Directory Structure:
datasets/<DATASET-NAME>/
├── annotation.json
└── images/
├── <image_id>.png
└── ...Annotation Format:
The annotation.json file must contain entries in this exact format:
{
"<image_id>": {
"split": "train", # {"train" or "val" if you don't want to train on these data but want to finetune on them}
"label": "your transcription text", # The ground truth text
"script": "Script_Type_Name", # Script category (hand or script type)
"page": "manuscript_page.jpg" # (optional) Source page reference, or other metadata
},
...
}👉 You can download and follow the instructions in this notebook to automatically create a Learnable Handwriter-compatible dataset.
Best Practices for Data Preparation
- Script Type selection: Prioritize articulated scripts where individual letters are well-separated over highly cursive writing. While cursive scripts can be tested, resulting prototypes can be blurry and not well modeled/defined.
-
Text Line Segmentation: Ensure accurate polygon segmentation with no surrounding letters or extraneous marks. Clean boundaries are critical for proper character modeling. Surrounding noise (like letters from previous lines) can create noise in the prototype.
 Example of good polygon segmentation.
Example of good polygon segmentation. - Alpha Channel: Always preserve the alpha channel in the extracted text line images.
- Text Orientation: Minimize text inclination whenever possible. Images should be as horizontally aligned as possible.
- Image Quality: Avoid images with ink spills, severe parchment damage, or excessive noise.
- Consistent Line Length: Maintain coherent line lengths throughout your dataset. Avoid mixing very short lines (e.g., from column layouts–manuscripts) with very long lines (e.g., lengthy charter lines). Inconsistent lengths can cause memory allocation issues during training.
-
High Contrast: Ensure strong contrast between ink and background. Poor contrast significantly impacts character recognition performance.
 Poor contrast affecting separation of the foreground from the background.
Poor contrast affecting separation of the foreground from the background. - Character Distribution: Make sure your dataset (or fine-tuning subset) contains at least 15–20 characters per character class, with >30 characters being optimal. Insufficient character examples lead to poor modeling of a character that is not reliable for palaeographical analysis.
Installation Setup
No GPU? You can still train models using our Google Colab notebook.
 Open Training Colab
Open Training Colab
Or perform inference on pre-trained and fine-tuned models:
Installation Steps
After cloning the repository and entering the base folder:
-
Create a conda environment:
conda create --name lhr python=3.10 conda activate lhr -
Install PyTorch:
Follow the official PyTorch installation guide for your system. Ensure CUDA compatibility if using GPU.
-
Install requirements:
python -m pip install -r requirements.txtTraining Visualization: Weights & Biases (wandb) is automatically installed for training process visualization and monitoring.
Training on Provided Dataset
To get started quickly with our reference dataset from the paper “An Interpretable Deep Learning Approach for Morphological Script Type Analysis (IWCP 2024)” :
-
Download and extract
datasets.zip - Run the training script:
python scripts/train.py iwcp_south_north.yaml
Fine-tuning Options
1. Script-based Fine-tuning (Northern and Southern Textualis):
python scripts/finetune_scripts.py -i runs/iwcp_south_north/train/ \
-o runs/iwcp_south_north/finetune/ \
--mode g_theta --max_steps 2500 --invert_sprites \
--script Northern_Textualis Southern_Textualis \
-a datasets/iwcp_south_north/annotation.json \
-d datasets/iwcp_south_north/ --split train2. Document-based Fine-tuning:
python scripts/finetune_docs.py -i runs/iwcp_south_north/train/ \
-o runs/iwcp_south_north/finetune/ \
--mode g_theta --max_steps 2500 --invert_sprites \
-a datasets/iwcp_south_north/annotation.json \
-d datasets/iwcp_south_north/ --split allTraining on Your Custom Data
Configuration Setup
The configuration system uses YAML files to define hyperparameters, dataset paths, and training settings. Each experiment requires both a dataset configuration and a main configuration file.
-
Create dataset config:
configs/dataset/<DATASET_ID>.yamlDATASET-TAG: path: <DATASET-NAME>/ sep: '' # Character separator in annotation space: ' ' # Space representation in annotation -
Create hyperparameter config:
configs/<DATASET_ID>.yamlFor concrete structure reference, see the provided config file for our iwcp_south_north experiment.
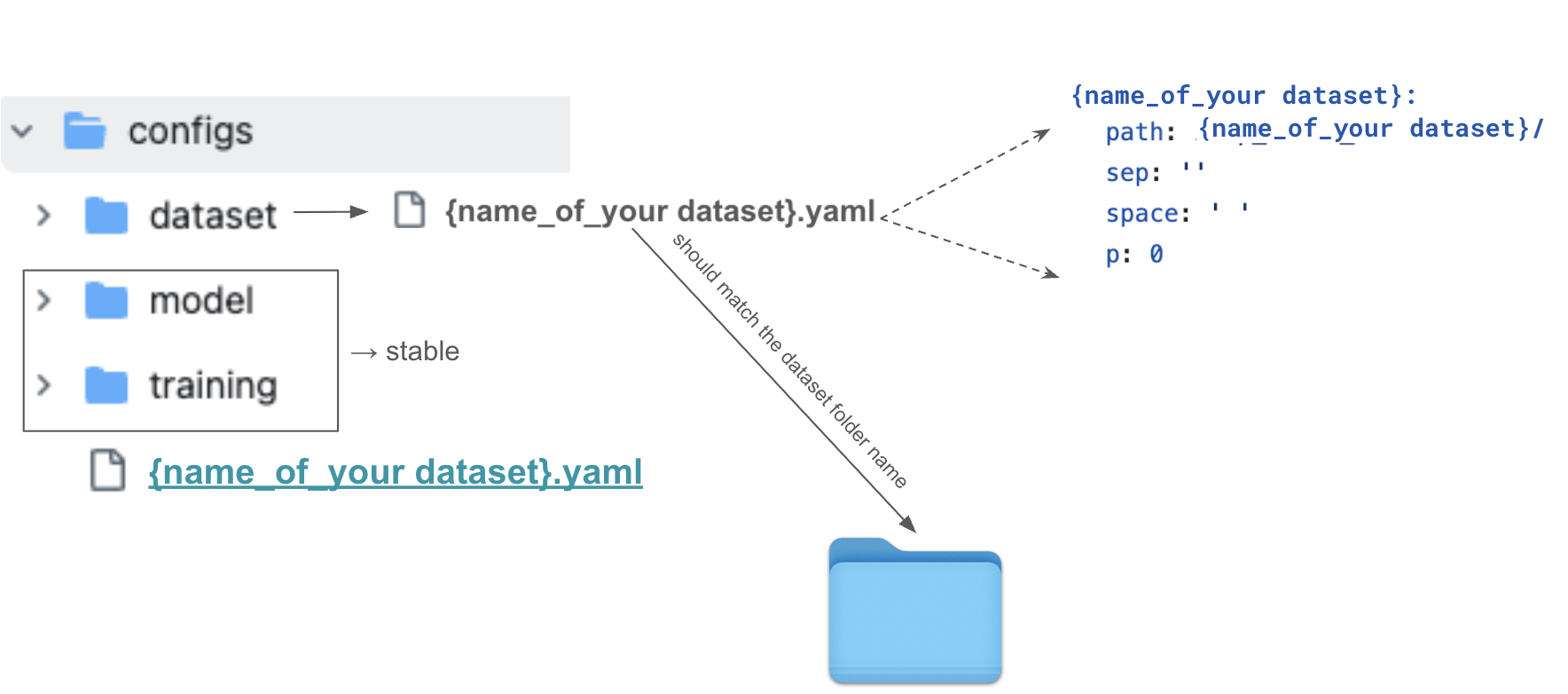
Training Process
-
Initial Training:
python scripts/train.py <CONFIG_NAME>.yaml -
Fine-tuning by Script Type:
python scripts/finetune_scripts.py -i runs/<MODEL_PATH>/ \ -o <OUTPUT_PATH>/ --mode g_theta --max_steps <int> \ --invert_sprites --script '<SCRIPT_NAME>' \ -a <DATASET_PATH>/annotation.json \ -d <DATASET_PATH>/ --split <train or all> -
Fine-tuning by Individual Documents:
python scripts/finetune_docs.py -i runs/<MODEL_PATH>/ \ -o <OUTPUT_PATH>/ --mode g_theta --max_steps <int> \ --invert_sprites -a <DATASET_PATH>/annotation.json \ -d <DATASET_PATH>/ --split <train or all>
📌 Technical Implementation Notes
- The system internally uses choco-mufin with a disambiguation-table.csv to normalize or exclude characters from annotations.
- Current configuration suppresses allographs and edition signs (e.g., modern punctuation) for consistent graphetic results.
- Character normalization ensures consistent analysis regardless of annotation source variations.