Defining script types and establishing classification criteria for medieval handwriting is a central aspect of palaeographical analysis. However, existing typologies often encounter methodological challenges, such as descriptive limitations and subjective criteria. We propose an interpretable deep learning-based approach to morphological script type analysis, which enables systematic and objective analysis and contributes to bridging the gap between qualitative observations and quantitative measurements. More precisely, we adapt a deep instance segmentation method called The Learnable Typewriter to learn comparable character prototypes, representative of letter morphology, and provide qualitative and quantitative tools for their comparison and analysis. We demonstrate our approach by applying it to the Textualis Formata script type and its two subtypes formalized by A. Derolez: Northern and Southern Textualis.
Analysis on Textualis Formata
Comparison between Derolez’ criteria for Northern (NT) and Southern Textualis (ST) and our subtype prototypes. We also report the standard deviations of character prototypes within one subtype (or intra-class variation), σNT for Northern Textualis and σST for Southern Textualis.
Figure 1: For our analysis, we trained multiple models to obtain character prototypes at different levels of granularity: (i) a script type model for Textualis, (ii) script subtype models for Northern and Southern Textualis, and (iii) document level models for each document in our dataset. We use the Textualis script type model as reference model, and finetune all other models from it.
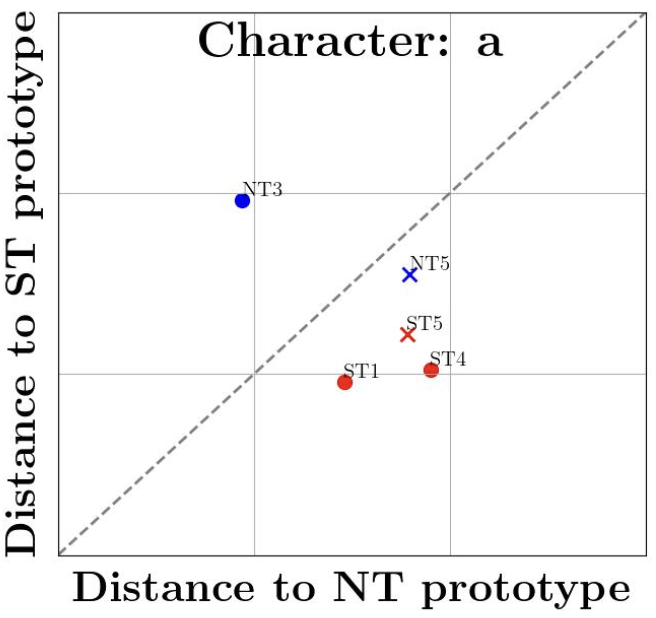
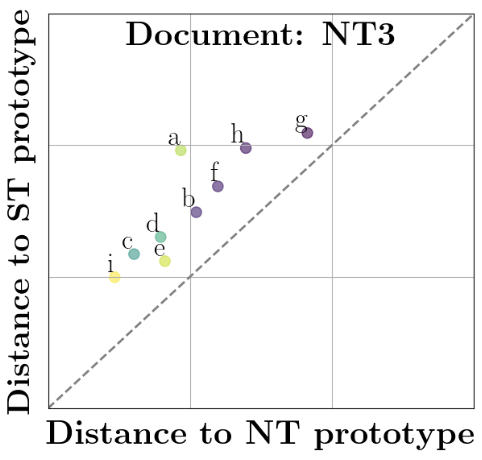
Figure 2: To quantitatively analyze character prototypes, we introduce an adapted comparison graph, where each point represents a specific document character prototype, with its coordinates defined as its distance in pixel space to two selected prototypes. We employ two complementary types of graphs for our analysis, Character and Document graphs. Blue, resp. red, markers signify Northern, resp. Southern Textualis documents.
Figure 2a: Character graphs concentrate on a single character across all documents.
Figure 2b: Document graphs concentrate on all characters across a document.
See the comparison graphs for all the characters and documents here.
References
The palaeography of Gothic manuscript books: From the twelfth to the early sixteenth century. Derolez, A. Cambridge University Press 2003.
@article{vlachou2024interpretable,
title = {An Interpretable Deep Learning Approach for Morphological Script Type Analysis},
author = {Vlachou-Efstathiou, Malamatenia and Siglidis, Ioannis and Stutzann, Dominique and Aubry, Mathieu},
publisher = {Document Analysis and Recognition--ICDAR 2021 Workshops: Athens, Greece, August 30--September 4, 2023, Proceedings},
year = {2024},
organization={Springer},
url={https://arxiv.org/abs/2408.11150}
}
Acknowledgements
This study was supported by the CNRS through MITI and the 80|Prime program (CrEMe Caractérisation des écritures médiévales), and by the European Research Council (ERC project DISCOVER, number 101076028). We thank Ségolène Albouy, Raphaël Baena, Sonat Baltacı, Syrine Kalleli, and Elliot Vincent for valuable feedback.